Hello,
I'm investigating the data and have a hard time recognizing the symptoms.
Now I just bumped upon a very spurious label if you ask me.
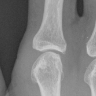
Patient 403 has erosion '5' on his right "pointing finger"
However.. that one looks fine to me.
But his left " pointing finger" is a "0" and it looks very bad.
If you ask me they are swapped.
Which is pretty bad since there are so few "5" labels already.
Right (5 label)
Left (0-label)
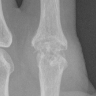
Created by Juul de puul juulepuul @lars.ericson, these limitations were known from the beginning, and are part of the challenge.
I think the sponsor would be satisfied to see that this competition produces algorithms that can automate a process which used to be tedious, time-consuming and dependent on subjective interpretation by radiologist.
Nobody says that the scoring would be perfect, but human scoring is not perfect either. It may turn out, as it appears in a few image interpretation fields, that on the average, there is less disagreement between a radiologist and the algorithm, than between 2 independent radiologists.
In this case this challenge would clearly be a success. @stadlerm I wasn't referring to dirty or unclear pictures, rather the swapping of left and right images, and within a single image, flipping so that a left foot looks like a right foot. Also to the lack of any training data at all for certain scale levels, so that we see 0,2,3,5 and never a 4. Which either reflects a clinical reality that arthritis immediately goes from 3 to 5, or that clinicians have a biased lens and tend to never diagnose a 4, or simply inadequate data. Assuming that a 4 is warranted, this leads to a categorical model which always misdiagnoses a 4 as a 3 or a 5, or imposes the choice of a regression model. Neither outcome is optimal and neither outcome makes for a very compelling paper. If I was a sponsor I would not want to be putting myself in the position of making such a weak argument. If I was a reviewer I would ding the paper. @lars.ericson I think you are sorely mistaken - nobody here is saying "don't fix the labels", in fact all top teams have argued that fixing the labels is vital.
What we've said is: if you can provide the fixed data in a reasonable time (let's say 2-3 weeks before the leadership round closes), then we don't need to delay the challenge further
Also note that there is teams that have found ways to deal with the dataset issues, and that is part of the challenage: variance in the data. The issue here is not dirty/unclear pictures or similar problems, but outright mistakes in the labels.
Nothing from the organizers has indicated that it will take months to fix the labels, so I think you are currently blowing things out of proportion. What you are asking for is a complete new dataset - to get a perfect ground truth you'd probably need 5 radiologists marking the images, and then create some sort of agreement gold standard from those. And to get a proper distribution of all examples, you will likely require a lot more patients.
Anyway, this whole discussion is pointless until we know an ETA for how long it will take to fix the labels. Understandably the current situation has priority, and whether a delay makes sense will depend on when the new labels are expected.
@dcentmakeover what we are seeing here may be understood as a conflict of interest between
* professional machine learning challenge solvers primarily incentivized by a cash payout, the sooner the better, and
* professional radiologist sponsors who are primarily incentivized by the reputational boost of a well-received paper.
What I am claiming is that the sponsors will suffer reputationally and risk rejection or a less prestigious venue for their research article, if they don't either
* find a ground truth radiologist who is not preoccupied by the pandemic to fix the data now, or they
* risk the displeasure and discomfort of the solvers by delaying the challenge until they can fix the data
By "fix the data" I mean provide clean (no flips and no swaps) training data which has at least one example for every level in the damage and erosion scales. @lars.ericson yes, i can work with that. It's OK. Sponsors will just have to open the final research article like this:
"Herein we describe the best method we could obtain with sparse training data containing correctable, visually obvious errors and lacking even single examples for some levels in our damage and narrowing scales. We could have fixed this and maybe got a more optimal method, but our ground-truth radiologist was busy fighting the epidemic, and our solvers didn't want to risk their current position on the Leaderboard. So please just take it all with a grain of salt. It's really good, anyway."
[First UK prisoner with COVID-19 confirmed at Strangeways Manchester](https://www.theguardian.com/world/2020/mar/18/first-uk-prisoner-with-covid-19-confirmed-at-strangeways-manchester) @dongmeisun @allawayr We agree as well - another extension seems unnecessary. The changed data should not impact method development, and ideally models only need to be retrained to be ready to go [Coronavirus Global Cases](https://www.arcgis.com/apps/opsdashboard/index.html#/bda7594740fd40299423467b48e9ecf6)
[Coronavirus cases exceed 1200 in Israel](https://www.haaretz.com/israel-news/coronavirus-cases-in-israel-surge-past-1-000-palestinian-pm-orders-lockdown-in-west-1.8700788)
[India goes on lockdown with 425 confirmed cases](https://timesofindia.indiatimes.com/city/mumbai/coronavirus-in-india-live-updates-janta-curfew-in-mumbai-delhi-bengaluru-chennai-hyderabad/liveblog/74754826.cms) @dongmeisun agree with @arielis , i hope the organisers don't extend the deadline once again.It is a bit exhausting dealing with altering timelines.thanks. Thanks a lot for suggestions.
Glad to let you know that we developed an approach to find errors. Swaps are not the only errors in the data set. The good thing is with the approach we developed we can easily find the errors and correct them. Because I have to work at home, it takes longer to fix these errors and get opportunity to be reviewed by specialist. Hope you all can understand this.
Hope you all keep social distance and stay safe. @dongmeisun
I don't think there is ground for an extension of the deadline, it has been significantly delayed already.
I would be happy to provide the organizers with scripts that allow to quickly identify possible swaps. As for the suggestion by @lars.ericson, this is exactly what I did to report the suspected swapped samples in the training set.
This should certainly be done on the evaluation sets, to detect possibly swapped scores.
However, I suspect swaps may not be the only pattern of error present, so I suggest that any consistent difference between the assigned labels and the scores predicted by the top performing models should be investigated (and in order to maintain objectivity, radiologist evaluation should be blinded to the labels or the results of the models).
Detecting error in the training set might be a bit more complicated since our models have learned from any error present, and might not be able to detect these as errors.
To all:
Thanks for your patient, effort and understanding. We are working hard to solve the issue, and will let you all know asap. Due to the data issue, we may extend the deadline for submission.
At this moment, I hope we all keep in safe. Blessings. @lars.ericson Really appreciate your suggestions and your patient. We are working on this, and will let you all know asap. For a reasonably well trained model we can run prediction on two image swap L/R of X and single image flip L/R to see if score aligns better with ground truth after swapping or rotation. Sponsors could do this with a better than baseline model as a data cleaning step. Hi @dongmeisun ,
Based on an automated analysis by my scoring model, there is good reason to suspect the following are swapped:
UAB032 feet
UAB037 hands
UAB045 feet
UAB046 feet
UAB067 hands
UAB144 feet
UAB297 feet
UAB317 hands
UAB383 feet
UAB403 hands
UAB458 hands
UAB549 feet
UAB648 hands
UAB690 feet Given this would there be any consideration to setting the challenge deadline a few months later? Hi, All:
We are reviewing all of the training images to fix any potential problems. However, our radiologist, Dr. Frazier, is in charge of operations for his department to respond to the evolving crisis. This may delay the availability of high quality training data. Hope you can understand this.
In addition, during this pandemic event, hope you all safely stay at home and spend more time to work on the challenge. Thanks for your understanding and support. Thank you very much Dear all,
As an update, some members of the organizing committee will be reviewing all of the training images and joints to flag mis-assigned labels like the one described above. Anything that is identified as an error in this first screen will be passed along to a radiologist to verify and correct. Once this is complete we'll release an updated training score matrix that corrects the error described in this thread and any others that are found. Hopefully this will lead to better performance for all!
We'll send out a participant wide announcement when this is complete.
Thanks,
Robert
Hi folks, just wanted to let you know that the steering committee for the challenge is discussing this and we'll get back to you ASAP. I am an MSK radiologist and I agree that these scores are simply flipped, left to right. As others have stated above, there is much interobserver and intraobserver variability that goes along with this scoring method. This case, however, is simply an error.
@dongmeisun @allawayr Truthfully, this is not an issue that should be solved later on. This massively impacts learning, especially in cases of such rare scores. Also in this case I don't think this is a disagreement between radiologists, but rather the labels are mixed up.
Reviewing this later is pointless, because if this is a repeated issues, even if just a few times (again, especially for such rare scores), the models will be forced to learn the wrong scores, which means it will never pop up as the model disagreeing. Honestly, I think, at least in the trainining data, we need to make sure to eliminate errors wherever possible. I would therefore urge you to at least check all these scores and make sure no others are further flipped or otherwise distorted
On the test/validation data it's a different story, and there it makes sense to maybe consider a radiologist if a fair share of models consistently disagree with some labels, but certainly not in this case.
Again, I want to stress that this isn't a simple disagreement between let's say a 2 or a 4, these are flipped labels from 0 to 5, which effectively means this whole datasample is useless, assuming the others are flipped as well. I would really urge you to try and fix those issues, in the training dataset, especially because we are already in a very challenging learning environment (few samples, rare labels, and so forth)
@juulepuul Good catch!
Thanks for pointing this. You are right @juulepuul , we also have same issue with UAB037 from previous discussion. As Robert said the scores generated by specialist, which could have errors. Please go ahead working on your algorithms since I believe most of the scores are correct. We will evaluate these "problem" scores when we assess the submissions as stated in the presentation of launching meeting "Significantly different will be reviewed by a musculoskeletal radiologist to determine accuracy of initial score vs predictions" (slide 23). To an untrained eye (like myself, i am biologist, not a clinician) the score does look like it might be flipped here. It's worth noting that these data represent scores from real radiologists, which means not every score will be perfect (and that two radiologists would likely give different scores for any particular joint). My inclination would be to simply state that is a limitation of working with real world data.
If you would prefer not to use this joint in training, or reassign the scores, that would be a reasonable approach.
What do the @RA2DREAMOrganizers think?